Context-free grammar of Tamizh language
Thoughts on Language semantics
Apart from programming languages, the language processing domain is always more about natural languages also. Every language has a set of input symbols, and rules. This so-called rule can be termed grammar, which is from a technical perspective of computer science. Let us analyze one already existing language which is my native language Tamizh, the language that I have more context in compared to any other language and in terms of syntax, grammar, etc. Before getting into grammar constructions, if we take a look into the symbols of the language, the Unicode 0b8c to 0bff, have been allotted for Tamizh. And letters will be created when combining two or more Unicode characters. Such as below,
ப + ஂ -> ப்
In Unicodes, (OBAA) + (OBCD) -> (OBAA)(OBCD)
There are 12 Uyir letters(vowels), 18 Mei (consonants), and both are collaborated and produce Uyir-mei, 216, letters. (And there is one special letter called Aayutham.) Totally 247 .uyir and mei collaborate in terms of both script-wise and sound-wise.
அ ஆ இ ஈ உ ஊ எ ஏ ஐ ஒ ஓ ஔ -> Vowels (Uyir)
A aa i ee u oo e ae ai o oa ou -> How it sounds
க் ங் ச் ஞ் ட் ண் த் ந் ப் ம் ய் ர் ல் வ் ழ் ள் ற் ன். -> Consonants (mei)
K ng ch nj t n th n p m y r l v zh lh tr nn -> How it sounds
So vowel+consonants create new letters, such as
க்+ அ-> க
K+ a -> ka
So for all other Uyir mei letters, rules can be derived from the same manner (mei+uyir), for a detailed chart, refer to this. There are some Grantha language letters mixed in Tamizh. From the phonetics point of view, there are two types of words(Sol) in Tamizh these are, Kuril (short sounded) and Nedil (long sounded). In vowels, அ இ உ எ ஒ, are Kuril as they sound short (a,i,u,e,o), and ஆ ஈ ஊ ஏ ஐ ஓ ஔ are nedil as they sound lengthier compared to above. And their respective Uyir-Mei falls under the same category. Mei letters are known as “Otru” since they don’t have significant sound length.
Syntax Grammar:
So this is the basic rule. In Unicode symbols, க has a single Unicode, so if we want to use consonants, we need to combine them with the Pulli (dot) operator. Because from the perspective of language mei is a separate letter, but from a Unicode point of view, two Unicode only make one mei letter, So the first series of uyir_mei letters, is naturally available in the Unicode character set itself. This series is க ங ச ஞ ட ண த ந ப ம ய ர ல வ ழ ள ற ன as uyir_mei_a, with this trick, our first rule for identifying consonants(mei) can be,
mei -> uyir_mei_a pulli
and rule for uyir_mei_a and pulli will be ,
uyir_mei_a -> க | ங | ச| ஞ |ட |ண |த | ந | ப | ம | ய | ர |ல |வ | ழ| ள | ற | ன
pulli -> ஂ
So we will have 4 types of letters, Uyir, Mei, Uyir mei, Aaytham and there are some Grantha letters that come into play. The letter is known as “Ezhuththu” in Tamizh, and the word is framed as “Sol”, and the sentence is known as “Vaakiyam”, and the paragraph will be “Paththi”. For recognizing the sentence and paragraph, just like any other language the basic rules are enough. The group of words (sol) can be coined as a sentence (Vaakiyam), and the group of sentences, and can be called as paragraph (Patthi).
Tamizh_script -> patthi+ ;
Patthi -> vaakiyam+;
vaakiyam -> sol+;
sol -> ezhuththu+;
Ezhuththu -> UYIR | MEI | AAYTHAM | UYIR_MEI_A … UYIR_MEI_OU | GRANTHA_SCRIPT_LETTERS
I have implemented full grammar for this syntactic parsing, using Antlr4, see the grammar here.
Semantics Grammar:
Tamizh has highly rich and structured grammatical rules at its core. The major parts are Ezhuthu Ilakkanam (letter grammar), Sol Ilakkanam (word grammar) , Porul ilakkanam (content grammar) , Yappu ilakkanam (compilation grammar) and Ani ilakkanam (decoration grammar).
Ezhuththu Ilakkanam talks about various properties of letters, such as the phonetics length of each letter, and how the last letter of one word and the first letter of another letter will change when both are joined, etc. Sol Ilakkanam talks about Nouns, Verbs, and their properties. To full fill, this, the knowledge-based system implementation is necessary using machine learning algorithms, etc.., And in another hand, Porul and Ani Ilakkanam completely focus on poetical tools, meanings and stories, so focusing on Yappu Ilakkanam (Compilation grammar) will make more sense to us for now, it can be the perfect part for semantic analysis.
In Yappu Ilakkanam, the top hierarchy of the parse tree is known as Venba, which exactly has CFG in itself.
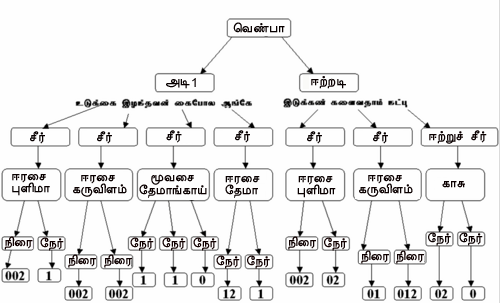
Tamizh Venba Grammar (src: Wiki)
You can see the full grammar here. And I have implemented it in Antlr4 in the same manner.
Once these rules are followed correctly, you will get the perfect rhythm in the poem. For example, the word used in Venba grammar is known as “Seer”. Based on the size, there are one to four sized seers. In two sized seers, there are Thema, Pulima, Koovilam and Karuvilam. As we have seen before, the two types of phonetics sounds (Kuril and Nedil) play major roles here. Based on them, these 4 categories are defined, each of them has a significant sound rhythm. I don’t want to dig into too much on Tamizh rules since this post is not entirely about that, I suggest you read more on that.
But the point is, there is a lot of reason for the existence of this entire Venba grammar thing in the language. The poets very well followed this rule while writing poems. In modern days, these rules are not followed, since we gave priority to music and content. But we can’t deny that once these rules exist, poets are able to write without compilers and parser tree generators. As we exist in the computer era, we can dig into these languages and their grammar more and more. In the future, I will try to write for other grammatical rules of this language, to discuss how natural languages can be defined by these contextual grammar and compiler theories.
Once these rules are followed correctly, you will get the perfect rhythm in the poem